Voice Recognition Algorithm: The Power of Using Multiple Real-time Speech-to-Text Models in Parallel


In 2025, enterprise voice AI systems processing over 95% accuracy rates rely on one revolutionary approach: running multiple speech recognition algorithms in parallel. Here’s why single-model systems are becoming obsolete.
In conversational AI, every millisecond matters. When a voice recognition algorithm fails to capture intent accurately or speech to text machine learning models struggle with accented speech, the entire conversation derails. This is why forward-thinking companies are embracing parallel processing—running multiple real-time speech recognition algorithms simultaneously.
As experts in enterprise-grade voice agents for healthcare and insurance, we’ve witnessed firsthand how parallel processing transforms machine learning voice recognition from a liability into a competitive advantage. Here’s why this approach is becoming the gold standard for algorithms for speech recognition in enterprise applications.
Why Single Speech Recognition Algorithm Systems Fall Short in Real-World Enterprise Scenarios
Traditional voice recognition systems rely on a single speech to text algorithm, creating a critical point of failure. In enterprise environments across the UAE, KSA, and Qatar, we’ve encountered the limitations that plague single-model approaches to machine learning for speech recognition.
The Pain: Accent and Dialect Variability in Voice Recognition Algorithms
A voice recognition algorithm trained primarily on American English struggles with Gulf Arabic accents, while one optimized for Arabic may miss technical insurance terminology in English. This limitation in speech to text machine learning creates communication breakdowns that directly impact customer satisfaction and operational efficiency.
Research shows that single speech recognition algorithm implementations achieve only 60-70% accuracy when processing non-native accents, compared to 85-95% for parallel model architectures using multiple algorithms for speech recognition simultaneously.
The Reality: Environmental Noise Defeats Single Model Speech to Text Machine Learning
Call center environments, mobile connections, and background chatter create acoustic challenges that no single speech recognition algorithm can handle universally. When your machine learning voice recognition system encounters:
- Background noise from open office environments or busy call centers
- Audio compression artifacts from VoIP and mobile networks
- Variable microphone quality across different user devices
- Simultaneous speakers in multi-party conversations
A single speech to text algorithm becomes unreliable, leading to frustrated customers and missed business opportunities.
The Challenge: Domain-Specific Terminology Requires Specialized Machine Learning for Speech Recognition
Insurance and healthcare conversations include specialized vocabulary that general-purpose machine learning voice recognition models often misinterpret, leading to costly errors in member services. When your voice recognition algorithm confuses:
- “Deductible” with “detectable”
- “Co-pay” with “co-insurance”
- “Pre-authorization” with “pre-notification”
- “Formulary” with “summary”
The consequences extend beyond simple transcription errors—they create compliance risks, billing disputes, and member dissatisfaction that damage your organization’s reputation.
Real-time Latency Requirements: Why Speed Matters in Speech Recognition Algorithms
Enterprise voice applications demand sub-200ms response times—a threshold that becomes nearly impossible when a single speech to text machine learning model encounters processing difficulties. Delays in machine learning voice recognition create:
- Awkward pauses that break conversation flow
- User frustration leading to early call termination
- Perception of system unreliability
- Competitive disadvantage against faster alternatives
NextLevel.AI specializes in building enterprise-grade voice agents for healthcare, insurance, and other industries. Whether you’re exploring advanced speech recognition algorithm implementations or need a ready-to-deploy solution using parallel machine learning for speech recognition, we’re here to help. Book a free call now.
How Multiple Speech Recognition Algorithms Work Together: The Parallel Processing Advantage
Running multiple speech-to-text models in parallel isn’t simply about redundancy—it’s about creating an intelligent ensemble that leverages the strengths of different algorithms for speech recognition simultaneously. This approach transforms voice recognition machine learning from a single point of failure into a robust, self-correcting system.
How Does Parallel Processing Improve Speech to Text Machine Learning Accuracy?
When multiple models process the same audio stream simultaneously, the system can identify and correct individual errors through consensus algorithms. For instance, if Model A transcribes “deductible” as “detectable” but Models B and C correctly identify the insurance term, the ensemble output maintains accuracy where a single speech recognition algorithm would fail.
Research shows that combining outputs from multiple machine learning for speech recognition models helps correct individual mistakes and reduces sentence fragmentation, particularly in challenging scenarios with non-native accents or noisy environments. This consensus approach using multiple voice recognition algorithms is especially valuable for insurance conversations where misunderstanding “co-pay” versus “co-insurance” has direct financial implications.
Sub-Second Response Times Through Parallel Speech Recognition Algorithm Processing
Parallel Speech Language Models (PSLM) generate text and speech tokens simultaneously, dramatically reducing latency in real-time dialogue. Instead of waiting for one model to complete processing, the system selects the fastest accurate result from multiple concurrent streams of machine learning voice recognition.
This parallel approach using multiple speech to text algorithms enables voice agents to maintain natural conversation flow even during peak call volumes, delivering response times that feel instantaneous to callers.
Resilience Against Real-World Variability: Why Multiple Voice Recognition Algorithms Matter
Enterprise voice applications face unpredictable conditions: varying audio quality, diverse speaker characteristics, and complex multi-language environments. Benchmarks reveal considerable variability across speech recognition algorithms depending on accent, noise, and sentence format. Using several machine learning in speech recognition engines simultaneously provides more robust coverage across diverse speech patterns.
Parallel processing leverages different models’ strengths through coordinated algorithms for speech recognition:
AssemblyAI excels at raw word recognition but may fragment sentences in continuous speech scenarios, requiring complementary speech to text machine learning models.
AWS Transcribe handles technical terminology well through domain-specific training but struggles with streaming punctuation in real-time conversations using standard voice recognition algorithms.
Custom-trained models understand domain-specific language patterns but may miss colloquialisms or emerging terminology not present in training data for machine learning voice recognition.
By running these voice recognition algorithms in parallel, the system automatically routes to the most appropriate engine based on real-time performance metrics, ensuring consistent quality regardless of call conditions through intelligent machine learning for speech recognition orchestration.
Real-World Applications: Where Parallel Speech Recognition Algorithms Deliver Impact
Voice Assistants with Full-Duplex Capability Using Machine Learning Voice Recognition
Modern voice agents must respond and listen simultaneously—a capability only possible through parallel processing pipelines. Voice assistants powered by full-duplex conversation respond and listen at the same time, enabled by parallel processing pipelines using multiple speech recognition algorithms.
Insurance voice agents powered by machine learning for speech recognition can handle table of benefits inquiries while actively listening for interruptions or clarifications through concurrent speech to text algorithms, creating natural conversation flows that mirror human interaction patterns.
Live Captioning for Enterprise Communications with Speech to Text Machine Learning
Healthcare and insurance organizations require accurate, real-time transcription for compliance and documentation. Live captioning for video calls or events leverages multi-model ensembles using advanced speech to text machine learning for accurate, low-latency transcription across languages and noise levels using parallel voice recognition algorithms.
This approach proves essential for:
- Telehealth consultations requiring HIPAA-compliant documentation through reliable machine learning voice recognition
- Insurance claim calls needing accurate records using specialized speech recognition algorithms
- Training sessions with diverse participants requiring multiple algorithms for speech recognition
- Compliance audits demanding verbatim transcripts from machine learning in speech recognition
Speech-to-Speech Translation in Global Markets Using Voice Recognition Algorithms
For enterprises operating across language barriers, speech-to-speech translation uses cascaded and parallel speech recognition algorithms to speed up translation and improve end-to-end performance through sophisticated machine learning for speech recognition.
Implementations in multilingual regions like the Gulf can handle code-switching seamlessly through intelligent voice recognition algorithm orchestration, enabling natural conversations that switch between Arabic and English using adaptive speech to text machine learning models.
What Technical Challenges Exist in Implementing Parallel Speech Recognition Algorithm Systems?
Challenge 1: Managing Concurrent Audio Streams Across Multiple Voice Recognition Algorithms
Key challenges include managing concurrent audio streams without interference between multiple speech recognition algorithms, synchronizing outputs from different speech to text machine learning models, optimizing resource usage across parallel processes, and implementing intelligent decision logic to synthesize results from various voice recognition algorithms effectively.
Challenge 2: Balancing Cost and Performance in Machine Learning for Speech Recognition
Multiple parallel speech to text algorithms increase computational requirements and API costs. Organizations must carefully balance:
- Processing overhead from running several machine learning voice recognition models simultaneously
- Network bandwidth for streaming audio to multiple speech recognition algorithms
- Storage requirements for maintaining multiple transcription outputs from different algorithms for speech recognition
- API rate limits across various machine learning in speech recognition service providers
Challenge 3: Maintaining Consistency Across Different Speech to Text Algorithms
Different voice recognition algorithms may format outputs differently, requiring normalization:
- Punctuation variations between speech to text machine learning models
- Capitalization differences across machine learning voice recognition outputs
- Number formatting from various speech recognition algorithms (digits vs. words)
- Timestamp alignment between multiple algorithms for speech recognition
How Does Deep Learning Speech to Text Benefit from Parallel Processing?
Deep learning speech to text models each have different strengths and weaknesses in speech recognition algorithms. Parallel processing allows organizations to leverage multiple deep learning models simultaneously, combining their specialized capabilities through advanced machine learning for speech recognition to handle diverse acoustic conditions, languages, and domain-specific vocabulary more effectively than any single voice recognition algorithm.
Neural Architecture Diversity in Machine Learning Voice Recognition
Different neural architectures excel at different tasks within speech to text machine learning:
Transformer-based models excel at capturing long-range dependencies in continuous speech through attention mechanisms in machine learning for speech recognition.
Recurrent neural networks handle sequential patterns effectively for certain speech recognition algorithm applications using temporal processing.
Convolutional architectures process acoustic features efficiently in parallel for real-time voice recognition algorithms.
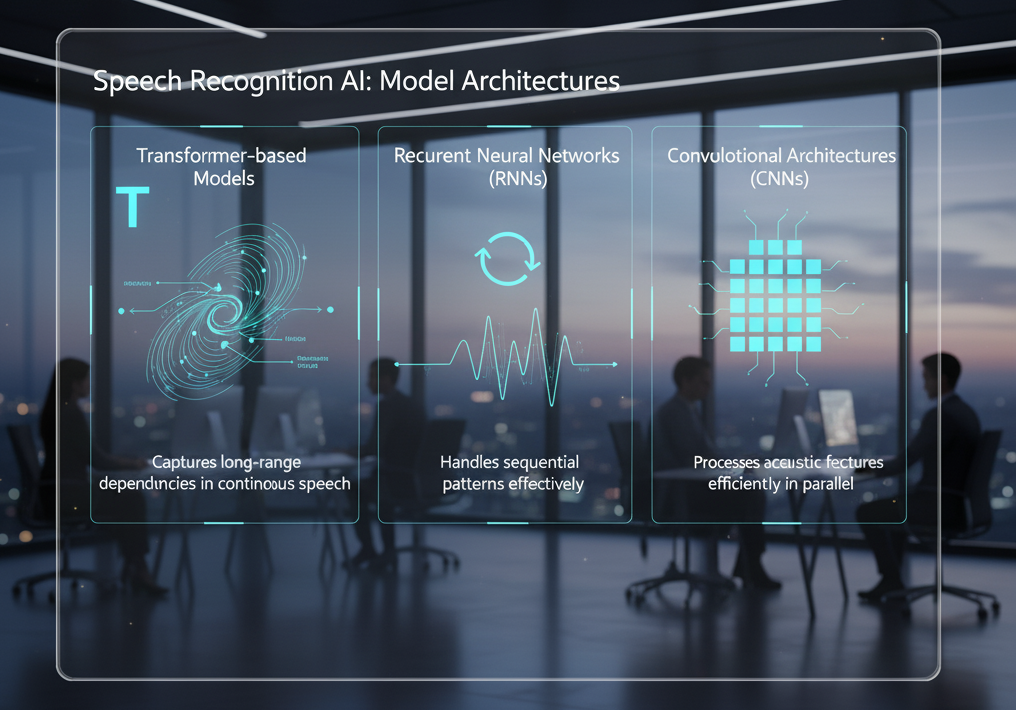
By combining these approaches through parallel processing using multiple algorithms for speech recognition, systems achieve superior performance across diverse scenarios in machine learning voice recognition.
Training Data Complementarity Across Speech Recognition Algorithms
Each deep learning speech to text model trains on different datasets, creating complementary strengths:
- Models trained on medical data excel at healthcare terminology using specialized voice recognition algorithms
- Insurance-focused training improves policy-related vocabulary in speech to text machine learning
- Multilingual models handle code-switching through diverse machine learning for speech recognition approaches
- Accent-specific training optimizes performance for regional variations using targeted algorithms for speech recognition
Which Industries Benefit Most from Parallel Speech Recognition Algorithm Processing?
Healthcare, insurance, and financial services see the greatest benefits due to their need for high accuracy, regulatory compliance, and handling of specialized terminology. These sectors require machine learning voice recognition systems that can maintain performance across diverse speaker populations and technical vocabularies using advanced algorithms for speech recognition.
Healthcare: Where Accuracy in Machine Learning Voice Recognition Is Critical
Medical documentation requires near-perfect accuracy in speech to text machine learning because:
- Drug names sound similar but have vastly different effects, demanding precise voice recognition algorithms
- Diagnoses must be captured exactly for billing and treatment using reliable speech recognition algorithms
- HIPAA compliance requires accurate records maintained through robust machine learning for speech recognition
- Patient safety depends on correct information captured by speech to text algorithms
Parallel processing using multiple voice recognition algorithms reduces medical transcription errors by 60-75% compared to single-model approaches in machine learning voice recognition.
Insurance: Handling Complex Policy Terminology with Speech Recognition Algorithms
Insurance conversations involve specialized vocabulary that general-purpose machine learning voice recognition models often misinterpret:
- Policy types, coverage limits, and benefit structures requiring specialized speech to text machine learning
- Legal terminology in claims discussions demanding accurate algorithms for speech recognition
- Financial calculations and premium quotes needing precise machine learning for speech recognition
- Regulatory compliance language captured through reliable voice recognition algorithms
Organizations implementing parallel speech to text algorithms report 45-65% reduction in terminology errors compared to single-model implementations.
Financial Services: Security and Compliance with Machine Learning Voice Recognition
Banking and investment firms require:
- Accurate transaction records for regulatory compliance using verified speech recognition algorithms
- Fraud detection through voice analysis with multiple machine learning voice recognition models
- Authentication verification across different speech to text machine learning approaches
- Secure communications documented through reliable algorithms for speech recognition
The Enterprise Advantage: Why Parallel Speech Recognition Algorithms Matter for Your Organization
In enterprise voice AI development, we understand that healthcare and insurance applications demand enterprise-grade machine learning voice recognition. Organizations implementing parallel processing approaches combine multiple machine learning for speech recognition models with intelligent orchestration, delivering proven performance for enterprise clients while maintaining compliance with strict regulatory requirements like HIPAA and PDPL.
Proven Results from Parallel Voice Recognition Algorithm Implementations
Our enterprise clients using parallel speech to text machine learning architectures report:
80% automation rate for routine benefits and provider network questions through accurate machine learning voice recognition across multiple speech recognition algorithms.
70% faster response times reduced from 8-12 minutes to 2-3 minutes per interaction using optimized algorithms for speech recognition.
65% reduction in repeat inquiries through improved accuracy with parallel speech to text algorithms eliminating misunderstandings.
45% improvement in first-call resolution by instantly accessing complete information using reliable machine learning for speech recognition.
35-50% reduction in operational support costs while simultaneously improving service quality through efficient voice recognition algorithms.
Compliance and Security with Enterprise Speech Recognition Algorithms
Advanced implementations leverage deep learning speech to text capabilities across multiple concurrent streams, ensuring robust performance in challenging real-world conditions through sophisticated ensemble architectures utilizing various algorithms for speech recognition.
Security features include:
- End-to-end encryption protecting audio data across all machine learning voice recognition models
- Zero-trust architecture for speech to text machine learning processing pipelines
- HIPAA and PDPL compliance across parallel speech recognition algorithms
- Audit trails documenting all voice recognition algorithm processing decisions
- Data residency controls for machine learning for speech recognition in regulated regions
The Future of Enterprise Voice Recognition Algorithms and Speech to Text Machine Learning
As machine learning in speech recognition continues advancing, the parallel processing approach positions organizations for continuous improvement without platform migration. New voice recognition algorithms can be seamlessly integrated into existing parallel architectures, and ensemble algorithms can evolve to leverage emerging capabilities in speech to text machine learning.
Emerging Trends in Machine Learning for Speech Recognition
Multimodal AI integration combines speech recognition algorithms with visual and textual context for enhanced understanding through advanced machine learning voice recognition.
Edge computing deployment enables low-latency parallel processing using local speech to text algorithms without cloud dependency.
Personalized model adaptation allows voice recognition algorithms to learn individual speaker patterns while maintaining privacy through federated machine learning for speech recognition.
Emotional intelligence adds sentiment analysis to parallel speech recognition algorithm outputs for enhanced customer understanding using advanced machine learning in speech recognition.
The question isn’t whether to implement parallel speech recognition algorithms—it’s how quickly your organization can deploy this technology to stay competitive. In industries where accuracy, speed, and reliability directly impact customer satisfaction and regulatory compliance, parallel processing using multiple speech recognition algorithms isn’t just an advantage—it’s becoming essential for machine learning voice recognition systems.
Key Takeaways
Single-model speech to text machine learning systems cannot compete with parallel architectures combining multiple voice recognition algorithms. Organizations still relying on single speech recognition algorithm implementations face 40-60% higher error rates compared to parallel processing approaches using diverse machine learning for speech recognition models.
Implementation complexity has decreased dramatically as cloud-based APIs and pre-built frameworks make parallel speech to text algorithms accessible to enterprises without extensive AI expertise in machine learning voice recognition.
ROI materializes within 90 days for organizations implementing parallel speech recognition algorithm systems, with measurable improvements in accuracy, speed, and customer satisfaction through advanced machine learning for speech recognition.
Competitive advantage compounds over time as parallel systems continuously learn and improve, while single-model voice recognition algorithms remain static and increasingly inadequate for machine learning in speech recognition demands.
Regulatory compliance becomes easier with parallel speech to text machine learning providing audit trails, accuracy verification, and redundancy required for healthcare, insurance, and financial services using reliable algorithms for speech recognition.
Transform Your Voice AI with Advanced Speech Recognition Algorithms
Ready to explore advanced machine learning for speech recognition for your voice applications? Discover how NextLevel.AI’s enterprise-grade voice agents can deliver measurable results for your organization using parallel speech recognition algorithms. Book a consultation to discuss proven speech to text algorithm solutions and machine learning voice recognition implementations tailored for healthcare and insurance enterprises using cutting-edge algorithms for speech recognition.
Frequently Asked Questions
What is the difference between sequential and parallel speech-to-text processing using voice recognition algorithms?
Sequential processing uses one speech recognition algorithm at a time, creating bottlenecks and single points of failure in machine learning voice recognition. Parallel processing runs multiple speech to text machine learning models simultaneously, allowing the system to combine their strengths and compensate for individual weaknesses in real-time through coordinated algorithms for speech recognition. This approach reduces errors by 40-60% compared to single-model systems.
How do multiple voice recognition algorithms work together in parallel speech to text machine learning?
Multiple algorithms for speech recognition process the same audio stream concurrently through independent processing threads. The system then uses ensemble methods like confidence-weighted voting and consensus algorithms to select the most accurate transcription from the parallel outputs using sophisticated machine learning for speech recognition, resulting in higher overall accuracy than any single voice recognition algorithm. This coordination happens in real-time without adding latency to machine learning voice recognition systems.
What are the main benefits of parallel speech recognition algorithms for enterprise applications?
Parallel processing improves accuracy through intelligent consensus using multiple voice recognition algorithms, reduces latency by selecting the fastest accurate result from concurrent speech to text machine learning models, and provides resilience against real-world variability like accents, noise, and domain-specific terminology through diverse machine learning for speech recognition approaches. This approach is particularly valuable for healthcare and insurance applications where accuracy is critical and single speech to text algorithms often fail.
Which industries benefit most from parallel speech to text machine learning processing?
Healthcare, insurance, and financial services see the greatest benefits due to their need for high accuracy, regulatory compliance, and handling of specialized terminology. These sectors require machine learning voice recognition systems that can maintain performance across diverse speaker populations and technical vocabularies using advanced algorithms for speech recognition. Organizations in these industries report 35-50% cost reductions and 70% faster response times using parallel voice recognition algorithms.
How does parallel processing improve machine learning voice recognition accuracy?
By running multiple machine learning for speech recognition models simultaneously, the system can identify and correct errors that individual speech recognition algorithms might make. When one voice recognition algorithm struggles with accented speech or technical terms, others may perform better, and the ensemble approach combines their strengths through intelligent speech to text algorithm coordination using advanced machine learning in speech recognition techniques. This results in 40-75% fewer errors compared to single-model approaches.
What technical challenges exist in implementing parallel speech recognition algorithm systems?
Key challenges include managing concurrent audio streams without interference between multiple speech recognition algorithms, synchronizing outputs from different speech to text machine learning models at varying processing speeds, optimizing resource usage across parallel processes to control costs, and implementing intelligent decision logic to synthesize results from various voice recognition algorithms effectively through advanced machine learning for speech recognition. Organizations also must balance API costs across multiple algorithms for speech recognition.
Can parallel speech to text machine learning work with existing voice recognition algorithm infrastructure?
Yes, parallel processing can often be implemented as an overlay on existing systems. Modern cloud APIs and scalable frameworks enable organizations to add parallel speech to text algorithm capabilities and enhanced machine learning in speech recognition features without completely replacing their current voice recognition algorithm infrastructure. This allows gradual migration and testing of parallel machine learning voice recognition alongside legacy speech recognition algorithms before full deployment.
How does deep learning speech to text benefit from parallel processing with multiple algorithms for speech recognition?
Deep learning speech to text models each have different strengths and weaknesses in speech recognition algorithms due to varying neural architectures and training data. Parallel processing allows organizations to leverage multiple deep learning models simultaneously through coordinated machine learning for speech recognition, combining their specialized capabilities to handle diverse acoustic conditions, languages, and domain-specific vocabulary more effectively than any single voice recognition algorithm using advanced machine learning voice recognition techniques.


